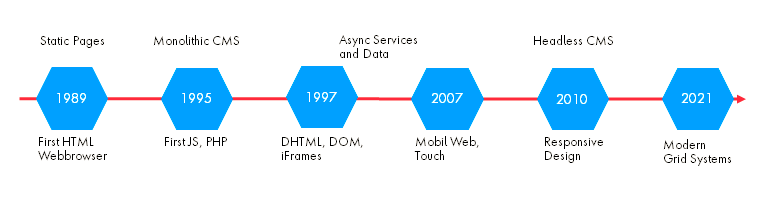
History of Content Management Systems
Content Management Systems as we use them today go back to the times when the Internet was invented by Tim Berners-Lee in 1990. Data and Content had to be stored somewhere — and even more important — had to be maintained and updated. Initially, most contents were created like documents, edited, and stored as static pages. This is enhanced with the need for dynamic content, interaction like commenting, or linking.
First CMS were still providing static HTML pages, that were rendered server-side by Script Languages like PHP, JSP, ASP, or other template languages or engines that have been created like TWIG, HTL, or Freemarker. Allowing to interact with the pages with added forms. Nowadays with Node as JavaScript (we cover this later)
This came with some problems as to how HTML is used, contents were only available in one format, and the source was created on a server that did not know anything about the device it was rendered on. With upcoming Mobile, but also other IoT devices it was hard to render this content appropriate on all devices.
What does this mean?
While the content was rendered into a unique layer of HTML on the server-side, only CSS was able to design this output. There was a hard binding from Content to HTML. This caused less flexibility and relaunch. Or re-using of content created effort in re-creating the server-side rendering. CSS could always re-create new designs with existing content if HTML is written properly. (Examples like CSS Zengarden are showing this for decades) But this heavily depends on semantic Markup and no Elements used that cause already design (like line breaks, <div> containers that represent design or similar).
Nowadays we can adjust layout and design with CSS and Media Queries. There were times when browsers were not supporting this well.
How do traditional CMS monoliths work?
A traditional CMS is a software that you either install and manage yourself or in a managed server environment. Traditional CMS is also known as “monolithic” because they contain all functions and assumptions for working in a single system. Traditional CMS often offers a visual authoring interface for editing content (WYSIWYG), as they only have one context for displaying the content — usually a website. The system normally offers a direct editing layer on an existing rendered layout.
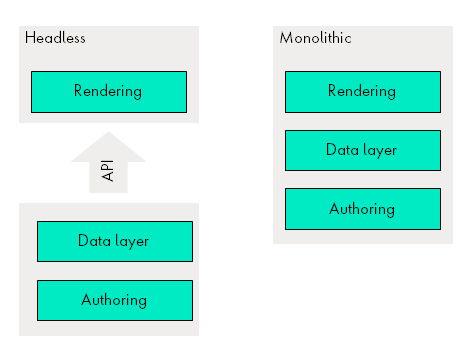
The headless CMS only contains a data layer and authoring. They provide an API for a headless rendering layer that consumes the data. The aforementioned is also one of the challenges. How can you render a WYSIWYG experience when your authoring system does not know about the rendering?
A new generation of CMS were invented. These often offer additionally Headless on existing systems, like CoreMedia for example, where besides Freemarker Template, a Headless GraphiQL server exists.
How to consume headless data
Headless also provides the possibility to get a content hub to ensure “Content first” implementation. Your one base of content will be able to maintain a bucket of additional endpoints.
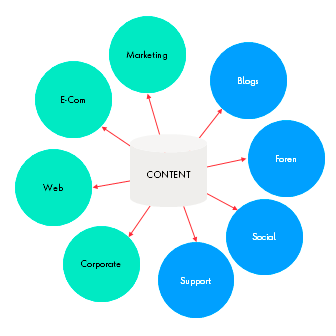
This data will be consumed via APIs — below are some examples.
Representational state transfer (REST)
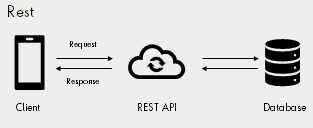
REST is a software architecture style that defines how to create web services. Web services, which conform to the REST architectural style and are known as RESTful Web Services, provide interoperability between computer systems on the Internet. RESTful web services allow the requesting systems to access and manipulate web resources using a set of stateless operations.
GraphQL
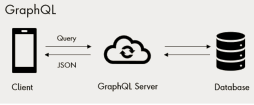
GraphQL is a query language for your API. Also, a server-side connection for executing queries belongs to a type of system to use for your data management. GraphQL is not tied to a personal database or storage engine and is driven by hidden code and data management.
A GraphQL service will have types and fields for those types. There are functions for each field from each type.
This is the rising star, as it offers flexibility not known before.
GROQ
I mention GROQ though it is not really widely used, but as I see similarities to GraphQL worth sharing.
Advantages
Use cases for headless CMS can be the following: You need to build a website with a technology you are familiar with, or web apps that use JavaScript frameworks like VUE, React, Svelte, Web Components, or Angular. Native mobile apps for iOS or Android can be directly consuming content. As you have seen, it’s not limited to websites.
Where headless helps:
- Your team is familiar with a special UI Technology.
- There is a need for A/B tests
- If you require a client-side rendered Framework like VUE, React, etc
- Personalization of Content
- If you have static side generators in place (Gatsby, Jekyll, Middleman, Next, Nuxt, or Eleventy)
- Mobile Apps or IoT
- If you need to enhance your E-Commerce data.
| Monolithic | Headless | |
| Simplicity | o | o |
| Localization | + | + |
| Plug-in Uncertainty | + | – |
| Cross-Platform | – | + |
| Technology Freedom | – | + |
| Developer first | – | + |
Drawbacks and Challenges
Editing your content can be harder for authors on headless systems. Your System is depending on a second screen/system.
Websites created with traditional CMS, allow customizable zones, and authors can resize and rearrange dynamic content easier. They are not limited to edit dynamic data in a fixed zone. They are enabled to share content easier.
With headless, authors often can’t customize the placement or presentation much beyond given forms, without implementing configurable content grids. Dragging and dropping components is getting harder, as the components only exist as data and rely on a presentation layer.
It can be more expensive to implement and the share of costs can get more complicated when only one unique source exists, but multiple layers consume it.
Search Engine Optimization can also be trickier. Server-side Rendering (SSR) needs to be implemented for deep linking. SSR makes it even more complex. There are some advantages with server-side rendered JavaScript, but it is still an effort to consider. Think twice before considering headless. There can be use-cases where all of the above is not relevant. Usage depends.
Conclusion
There is no black and white decision possible. It depends on your team’s skills, your client’s or customers‘ needs, your project setup, and so on. Just make the right decision in the beginning.